SimUSER
Simulating User Behavior with Large Language Models for Recommender System Evaluation
Abstract
Recommender systems play a central role in numerous real-life applications, yet evaluating their performance remains a significant challenge due to the gap between offline metrics and online behaviors. Given the scarcity and limits (e.g., privacy issues) of real user data, we introduce SimUSER, an agent framework that serves as believable and cost-effective human proxies. SimUSER first identifies self-consistent personas from historical data, enriching user profiles with unique backgrounds and personalities. Then, central to this evaluation are users equipped with persona, memory, perception, and brain modules, engaging in interactions with the recommender system. SimUSER exhibits closer alignment with genuine humans than prior work, both at micro and macro levels. Additionally, we conduct insightful experiments to explore the effects of thumbnails on click rates, the exposure effect, and the impact of reviews on user engagement. Finally, we refine recommender system parameters based on offline A/B test results, resulting in improved user engagement in the real world.
Key Results
(vs. 69.1% Agent4Rec)
(vs. 0.76 Agent4Rec)
(5-point scale)
(Spearman's rho)
Overview
SimUSER provides a framework for systematically assessing recommender systems by engaging in interactions and providing feedback. The methodology consists of two phases: (1) self-consistent persona matching from historical data, and (2) interactive recommender system evaluation with persona-equipped agents.
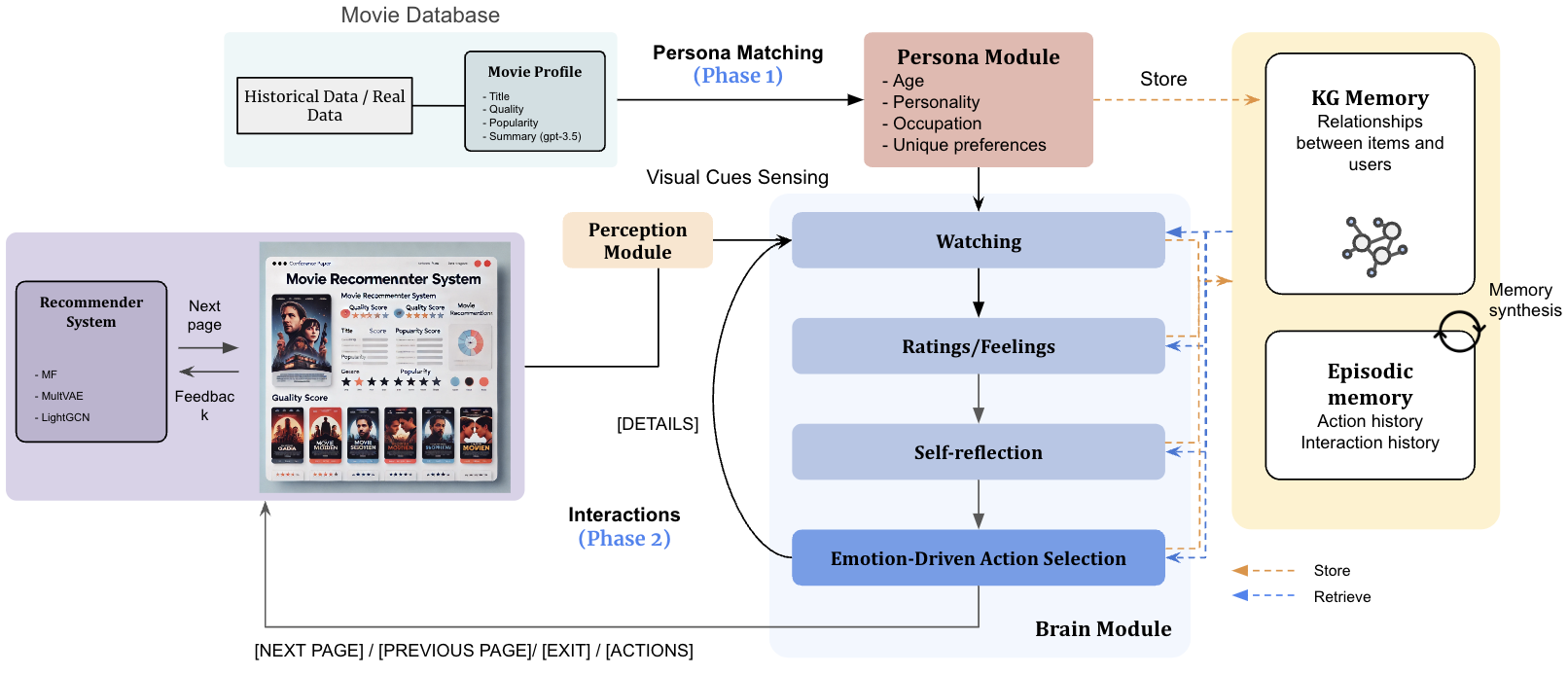
Figure 1: The SimUSER framework for evaluating a movie recommender system, featuring persona matching and four agent modules: persona, perception, memory, and brain.
Agent Architecture
Each SimUSER agent is equipped with four specialized modules:
Persona Module
Stores matched persona along with pickiness level, habits, and unique tastes. Personas include age, Big Five personality traits, and occupation inferred through self-consistency scoring.
Perception Module
Integrates visual cues from item thumbnails via image-derived captions, capturing emotional tones and visual details that influence human decision-making.
Memory Module
Comprises episodic memory for interaction history and knowledge-graph memory to capture user-item relationships through path-based similarity retrieval.
Brain Module
Translates retrieved evidences into action plans using multi-round preference elicitation, item evaluation, action selection, causal refinement, and post-interaction reflection.
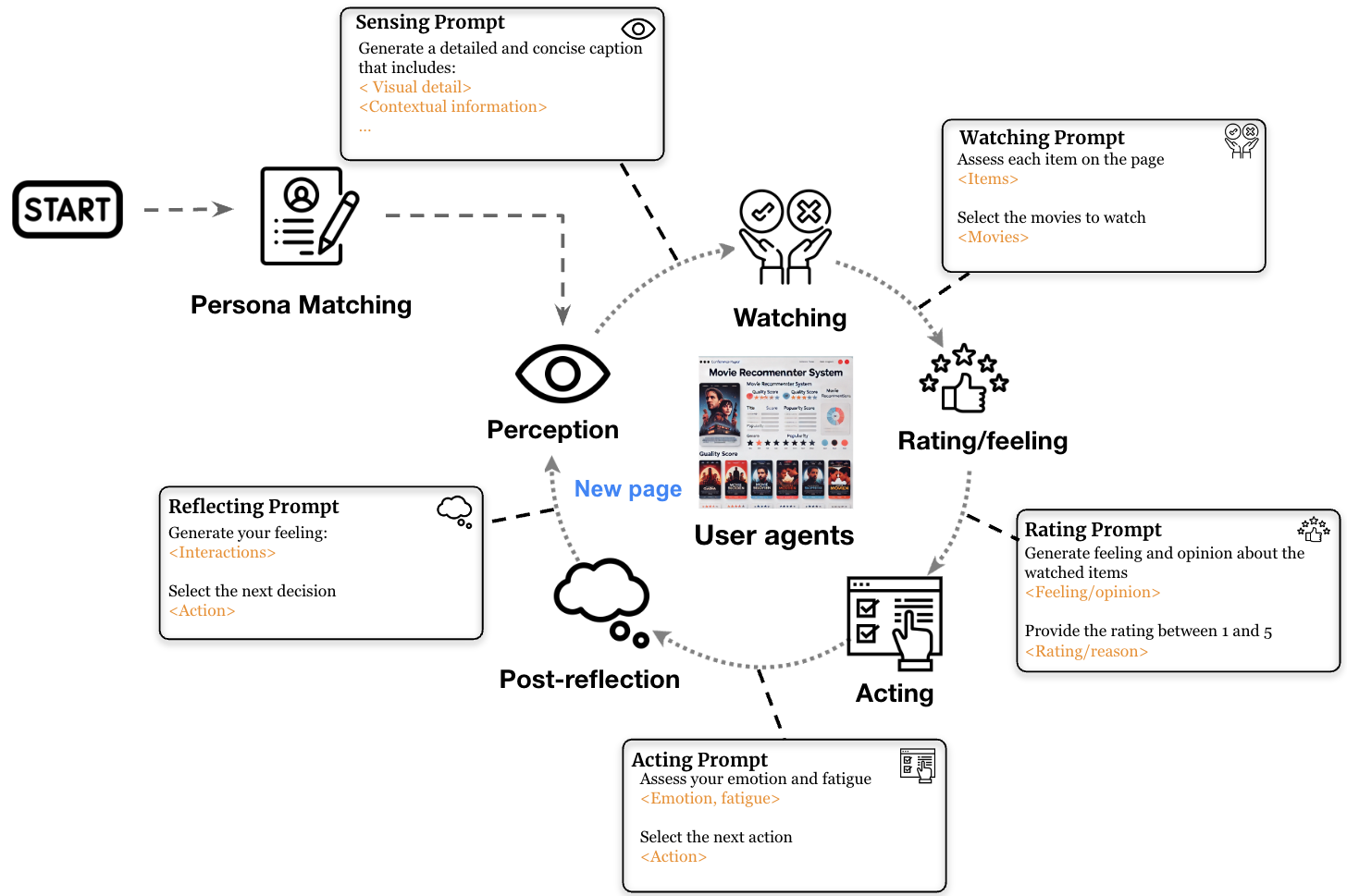
Figure 2: The Brain Module workflow showing the interaction cycle: Persona Matching leads to iterative Watching, Rating/Feeling, Acting, and Post-reflection phases. Each step uses specialized prompts to generate human-like behavior.
Experiments
Preference Alignment
We evaluate whether agents can identify items aligned with their human counterparts' tastes across different distractor levels:
| Method | MovieLens | AmazonBook | Steam | |||
|---|---|---|---|---|---|---|
| (1:1 ratio) | Acc | F1 | Acc | F1 | Acc | F1 |
| RecAgent | 0.581 | 0.621 | 0.604 | 0.659 | 0.627 | 0.650 |
| Agent4Rec | 0.691 | 0.698 | 0.719 | 0.700 | 0.689 | 0.679 |
| SimUSER | 0.791 | 0.777 | 0.822 | 0.790 | 0.791 | 0.794 |
Rating Prediction
SimUSER achieves substantially lower rating prediction error than all baselines:
| Method | MovieLens | AmazonBook | Steam | |||
|---|---|---|---|---|---|---|
| RMSE | MAE | RMSE | MAE | RMSE | MAE | |
| RecAgent | 1.102 | 0.763 | 1.259 | 1.119 | 1.077 | 0.960 |
| Agent4Rec | 0.761 | 0.714 | 0.879 | 0.671 | 0.758 | 0.688 |
| SimUSER | 0.502 | 0.446 | 0.568 | 0.421 | 0.587 | 0.532 |
Human-Likeness Evaluation
GPT-4o assessed whether agent interactions appear human or AI-generated using a 5-point Likert scale:
| Method | MovieLens | AmazonBook | Steam |
|---|---|---|---|
| RecAgent | 3.01 | 3.14 | 2.96 |
| Agent4Rec | 3.04 | 3.21 | 3.09 |
| SimUSER | 4.41 | 3.99 | 4.02 |
Datasets
SimUSER is evaluated on three diverse recommendation domains:
- MovieLens-1M: Movie ratings and reviews
- AmazonBook: Book ratings from Amazon
- Steam: Video game ratings and reviews