Generative Reviewer Agents
Scalable Simulacra of Peer Review
Abstract
The peer review process is fundamental to scientific progress, determining which papers meet the quality standards for publication. Yet, the rapid growth of scholarly production and increasing specialization in knowledge areas strain traditional scientific feedback mechanisms. In light of this, we introduce Generative Agent Reviewers (GAR), leveraging LLM-empowered agents to simulate faithful peer reviewers. To enable generative reviewers, we design an architecture that extends a large language model with memory capabilities and equips agents with reviewer personas derived from historical data. Our experiments demonstrate that GAR performs comparably to human reviewers in providing detailed feedback and predicting paper outcomes. Beyond mere performance comparison, we conduct insightful experiments, such as evaluating the impact of reviewer expertise and examining fairness in reviews. By offering early expert-level feedback, typically restricted to a limited group of researchers, GAR democratizes access to transparent and in-depth evaluation.
Key Results
(vs. 0.523 Human)
Prediction Accuracy
(5-point scale)
(vs. 0.49 Human)
Overview
GAR employs a 4-phase pipeline to simulate the peer review process: (1) Graph Construction to structure the manuscript, (2) Reviewer Selection with persona initialization, (3) Multi-round Reviewer Evaluation, and (4) Meta-Review synthesis for final decisions.
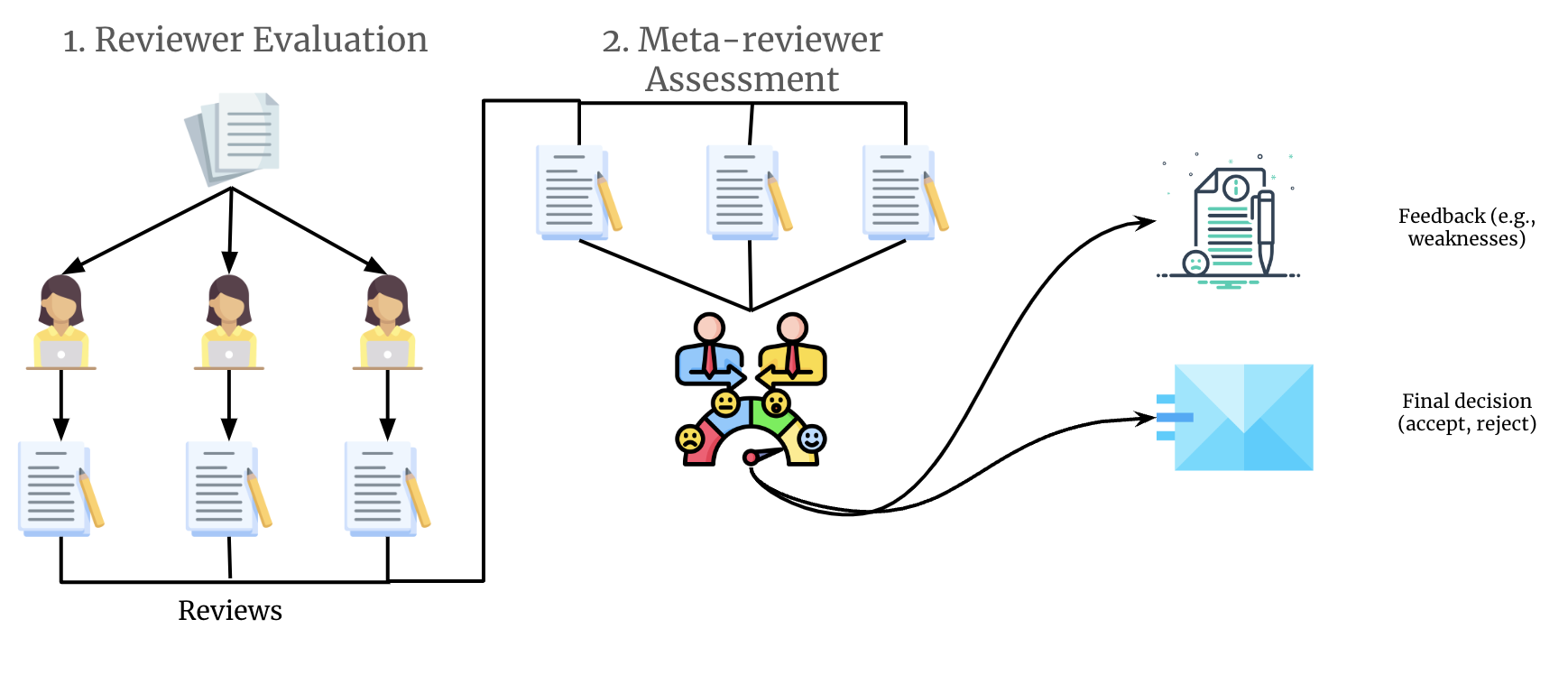
Figure 1: The Generative Agent Reviewers (GAR) framework for simulating peer review, featuring graph-based paper representation, memory-augmented reviewers, and multi-round evaluation.
Reviewer Agent Architecture
GAR structures agents with four specialized modules tailored for review scenarios:
Profile Module
Stores eight core attributes: strictness, expertise level, focus areas, evidence focus, open-mindedness, ethic focus, tone, and attention to technical details. Characteristics are inferred via contrastive comparison across reviews.
Novelty Module
Draws upon external knowledge sources (Semantic Scholar) to gauge the originality of the manuscript in comparison to prior research, generating novelty scores with explanations.
Memory Module
Enables retrieval-augmented reviews through community-level retrieval (similar communities and reviews) and paper-level retrieval (similar papers based on graph overlap).
Review Module
Generates initial reviews and performs multi-round refinement, evaluating each community descriptor with retrieved exemplars from memory to identify strengths and weaknesses.
Graph-Paper Representation
To handle lengthy and complex manuscripts, GAR introduces a graph-based representation that organizes content into structured communities:
- Acronym Extraction: Identifies acronyms and definitions from title, abstract, and introduction
- Core Element Extraction: Identifies ideas, claims, technical details, and supporting evidence as nodes
- Concept Merging: Reduces redundancy by merging similar concepts across the manuscript
- Community Detection: Uses Leiden algorithm to partition the graph into thematic clusters
- Community Descriptors: Generates report-like summaries for each community
Experiments
LLM vs Human Review Preferences
We evaluated review quality using GPT-4 preferences in pairwise comparisons:
| Rank | Reviewer | Bradley-Terry Score |
|---|---|---|
| 1 | GAR | 0.684 |
| 2 | Human | 0.523 |
| 3 | AI-Scientist | 0.242 |
| 4 | ReviewerGPT | 0.000 |
| 5 | AI-Review | -0.365 |
| 6 | OpenReviewer | -0.632 |
Predicting Paper Acceptance
We compared GAR's decisions against ground truth from NeurIPS and ICLR submissions:
| Method | NeurIPS | ICLR 22 | ICLR 23 | |||
|---|---|---|---|---|---|---|
| Bal. Acc | F1 | Bal. Acc | F1 | Bal. Acc | F1 | |
| Human* | 0.66 | 0.49 | 0.66 | 0.49 | 0.66 | 0.49 |
| AI-Scientist | 0.58 | 0.51 | 0.65 | 0.57 | 0.63 | 0.55 |
| AI-Review | 0.59 | 0.49 | 0.64 | 0.55 | 0.61 | 0.53 |
| GAR | 0.64 | 0.61 | 0.68 | 0.66 | 0.66 | 0.60 |
| GAR> | 0.68 | 0.62 | 0.71 | 0.67 | 0.70 | 0.69 |
*Human scores from NeurIPS 2021 consistency study. GAR> uses threshold-based acceptance.
Human-Likeness Evaluation
GPT-4o assessed whether reviews appeared AI-generated or human-like (5-point scale):
| Method | NeurIPS | ICLR 22 | ICLR 23 |
|---|---|---|---|
| AI-Scientist | 3.34 | 3.39 | 3.38 |
| AI-Review | 3.30 | 3.42 | 3.38 |
| ReviewerGPT | 3.26 | 3.25 | 3.29 |
| GAR | 3.89 | 4.02 | 3.99 |
Feedback Aspect Comparison
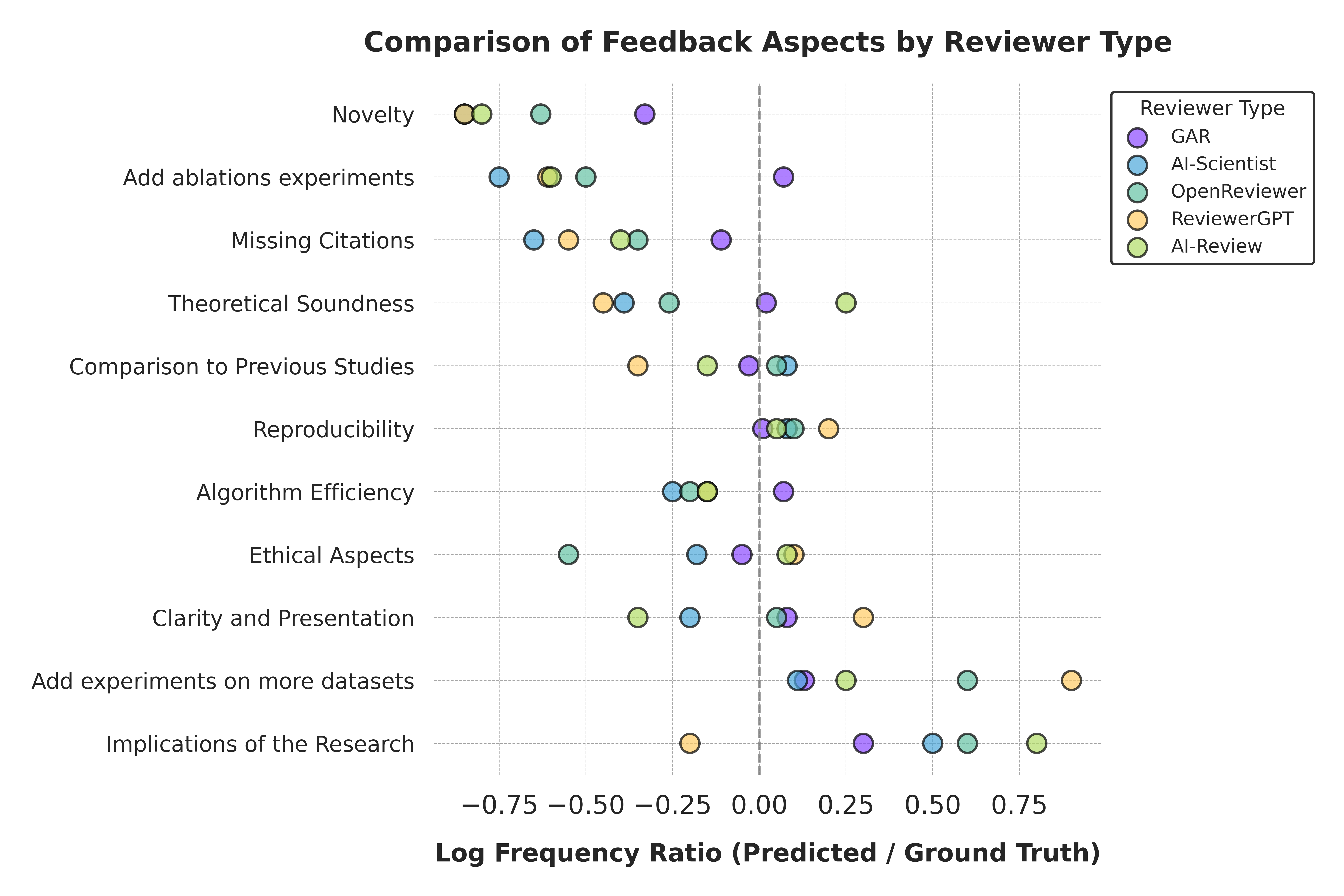
Figure 2: Comparison of feedback aspects across different reviewer types. GAR (purple) shows closer alignment to ground truth (0.0 baseline) on most dimensions including novelty assessment, theoretical soundness, and ethical aspects, while baseline methods tend to deviate more significantly.
Datasets
GAR is evaluated on peer review datasets from major ML conferences:
- ICLR 2022: 3,797 papers with full reviews from OpenReview
- ICLR 2023: Conference submissions with reviewer feedback
- NeurIPS 2023: Papers from the NeurIPS proceedings