AlignUSER
Human-Aligned LLM Agents via World Models for Recommender System Evaluation
Abstract
Evaluating recommender systems remains challenging due to the gap between offline metrics and real user behavior, as well as the scarcity of interaction data. Recent work explores large language model (LLM) agents as synthetic users, yet they typically rely on few-shot prompting, which yields a shallow understanding of the environment and limits their ability to faithfully reproduce user actions. We introduce AlignUSER, a framework that learns world-model-driven agents from human interactions. Given rollout sequences of actions and states, we formalize world modeling as a next state prediction task that helps the agent internalize the environment. To align actions with human personas, we generate counterfactual trajectories around demonstrations and prompt the LLM to compare its decisions with human choices, identify suboptimal actions, and extract lessons. The learned policy is then used to drive agent interactions with the recommender system. We evaluate AlignUSER across multiple datasets and demonstrate closer alignment with genuine humans than prior work, both at the micro and macro levels.
Key Results
(vs. 24.2% prior best)
(vs. 0.50 SimUSER)
(5-point scale)
Overview
AlignUSER learns to simulate realistic user behavior by combining two key insights: (1) agents should understand how the world works through next-state prediction, and (2) agents should align with human decisions through counterfactual reasoning. The framework first pretrains on environment dynamics, then learns from comparing human actions with alternative trajectories.
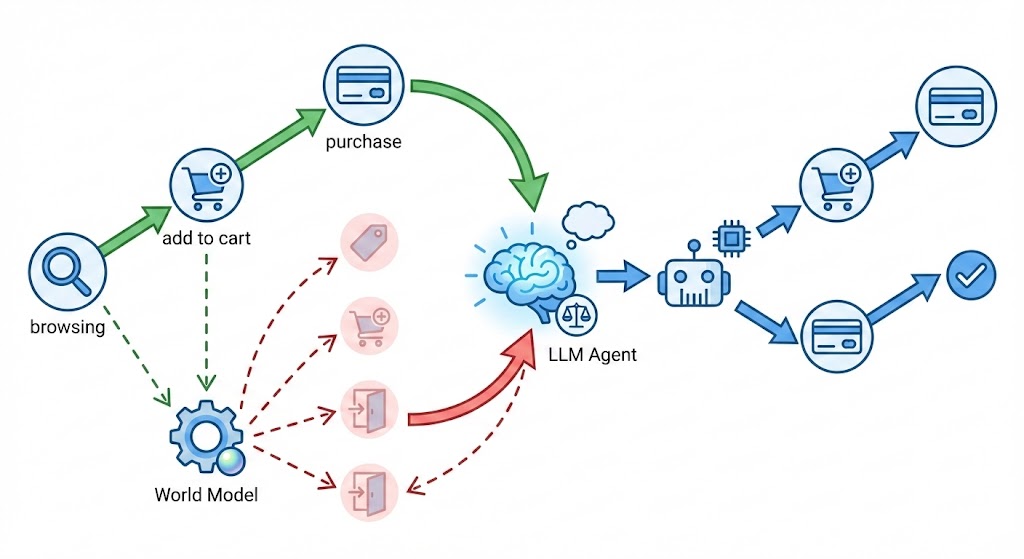
Figure 1: The AlignUSER framework for evaluating a recommender system by implicitly modeling a world model and exploring alternative scenarios. Green arrows show the human trajectory; red dashed arrows show counterfactual alternatives explored by the world model.
Motivation
Existing LLM-based user simulators rely on few-shot prompting, treating the agent policy as a black box without explicit understanding of how actions shape future states. This leads to shallow behavior that reflects the model's priors rather than genuine user patterns. AlignUSER addresses this through:
World Modeling
Train the agent to predict next states from state-action pairs, helping it internalize environment dynamics (e.g., clicking a product leads to a detail page).
Counterfactual Reasoning
Generate alternative trajectories and prompt the LLM to compare them with human actions, identifying why human choices are better aligned with persona and context.
Policy Learning
Train the policy to jointly predict chain-of-thought reasoning and expert actions, creating an agent that understands both what to do and why.
Counterfactual Reflection
For each human transition, we sample alternative actions that the current policy considers plausible but differ from the demonstrated action. The agent then reasons about why the human choice is better in context, more aligned with persona, and leads to better future outcomes.
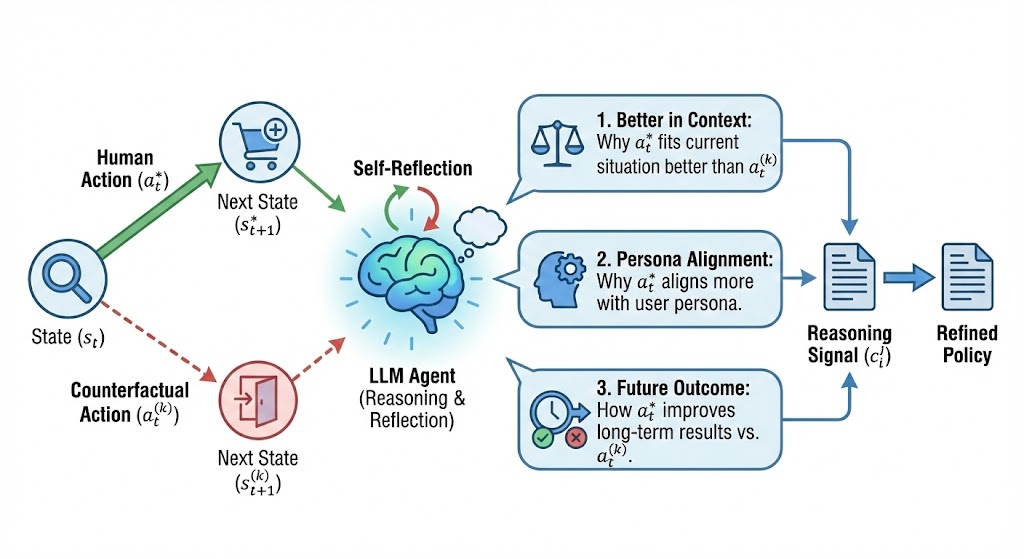
Figure 2: Counterfactual reflection from counterfactual trajectories. The LLM agent compares human actions with alternatives, generating reasoning signals that explain (1) contextual fit, (2) persona alignment, and (3) long-term outcome improvement.
Experiments
Preference Alignment
We evaluate whether agents can identify items aligned with their human counterparts' tastes. AlignUSER significantly outperforms baselines across all datasets and distractor levels.
| Method (1:1) | MovieLens | AmazonBook | Steam | |||
|---|---|---|---|---|---|---|
| Acc | F1 | Acc | F1 | Acc | F1 | |
| RecAgent | 0.581 | 0.621 | 0.604 | 0.659 | 0.627 | 0.650 |
| Agent4Rec | 0.691 | 0.698 | 0.719 | 0.700 | 0.689 | 0.679 |
| SimUSER | 0.791 | 0.777 | 0.822 | 0.790 | 0.791 | 0.794 |
| AlignUSER | 0.820 | 0.817 | 0.843 | 0.830 | 0.814 | 0.834 |
| AlignUSER+ | 0.832 | 0.827 | 0.855 | 0.842 | 0.827 | 0.846 |
Rating Prediction
AlignUSER achieves substantially lower rating prediction error than all baselines, demonstrating better understanding of user preferences.
| Method | MovieLens | AmazonBook | Steam | |||
|---|---|---|---|---|---|---|
| RMSE | MAE | RMSE | MAE | RMSE | MAE | |
| Agent4Rec | 0.761 | 0.714 | 0.879 | 0.671 | 0.758 | 0.688 |
| SimUSER | 0.502 | 0.446 | 0.568 | 0.421 | 0.587 | 0.532 |
| AlignUSER | 0.469 | 0.415 | 0.513 | 0.399 | 0.534 | 0.501 |
| AlignUSER+ | 0.429 | 0.387 | 0.465 | 0.374 | 0.497 | 0.483 |
Action Alignment
On next-action prediction, AlignUSER dramatically outperforms both general-purpose LLMs and specialized user simulation methods.
| Model | Action Gen. (Acc) | Action Type (F1) | Click Type (F1) | Session Outcome (F1) |
|---|---|---|---|---|
| 21.51 | 48.78 | 44.47 | 47.54 | |
 Claude-3.7 Claude-3.7 |
10.75 | 31.58 | 27.27 | 43.52 |
 Llama-3.3 Llama-3.3 |
8.31 | 24.29 | 19.99 | 36.64 |
| SimUSER | 24.21 | 52.44 | 48.68 | 59.63 |
| 51.47 | 69.81 | 66.29 | 78.07 | |
| 52.92 | 71.94 | 66.88 | 80.52 |
Thought and Persona Consistency
On the OPeRA dataset with human rationales, AlignUSER achieves 89.3% thought-action consistency and produces session statistics closest to real human behavior.
| Method | Thought-Action (%) | Persona-Behavior (%) | Pages/Session | Purchase Gap (%) |
|---|---|---|---|---|
| Human (OPeRA) | -- | -- | 5.3 | -- |
| RecAgent | 49.5 | 46.7 | 3.5 | 16.3 |
| Agent4Rec | 55.8 | 52.4 | 4.0 | 12.1 |
| SimUSER | 64.3 | 61.5 | 4.6 | 9.9 |
| AlignUSER | 86.7 | 82.4 | 5.1 | 2.5 |
| AlignUSER+ | 89.3 | 85.6 | 5.1 | 2.1 |
Datasets
We evaluate AlignUSER on four diverse datasets spanning different recommendation domains:
- MovieLens-1M: ~1 million movie ratings from 6,040 users over 3,706 movies
- Steam: User-game interactions with English-language reviews
- AmazonBook: Book ratings and reviews from Amazon
- OPeRA: Real-world shopping sessions with persona surveys, actions, and self-reported rationales